背景信息
Alpaca大模型是一款基于LLaMA的大语言模型,它可以模拟自然语言进行对话交互,并协助用户完成写作、翻译、编写代码、生成脚本等一系列创作任务。同时,使用了中文数据进行二次预训练,提升了中文基础语义理解能力。
本文基于阿里云GPU服务器和Alpaca大模型,指导您如何快速搭建个人版“对话大模型”。
重要
- 阿里云不对第三方模型Alpaca大模型的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
- 您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
创建并配置ECS实例
- 在ECS实例创建页面,创建ECS实例。关键参数说明如下,其他参数的配置,请参见自定义购买实例。
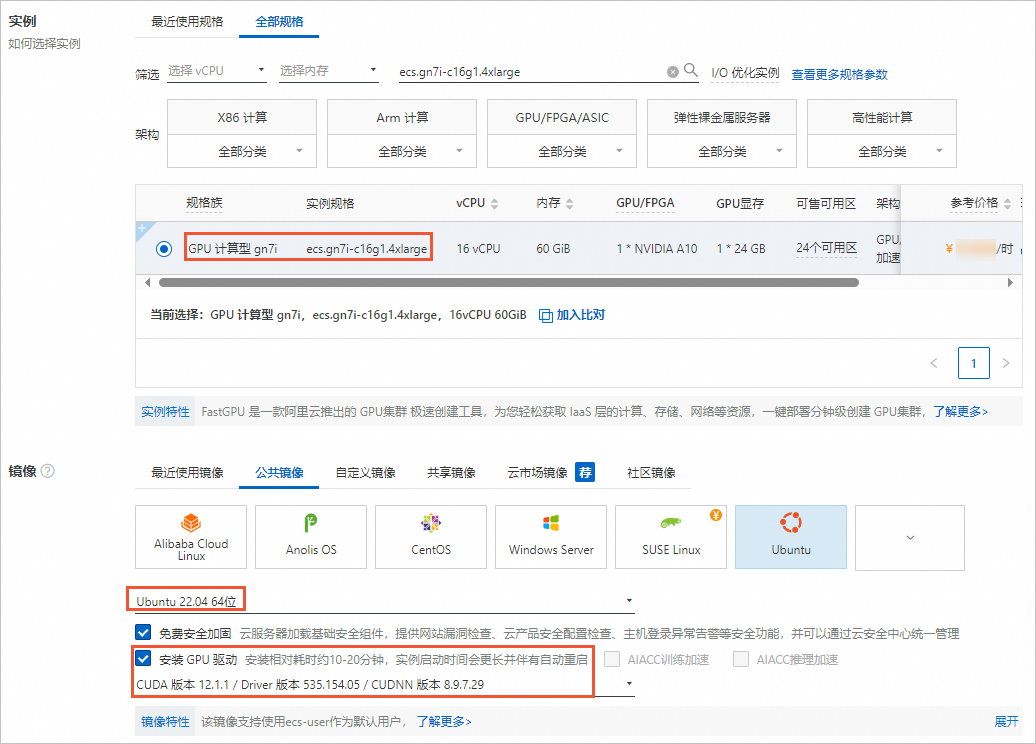
- 实例规格:选择实例规格为ecs.gn7i-c16g1.4xlarge。
- 镜像:公共镜像Ubuntu 22.04,并选中安装GPU驱动,选择CUDA 版本12.1.1/Driver 版本535.154.05/CUDNN 版本8.9.7.29。
- 系统盘:不小于200 GiB。
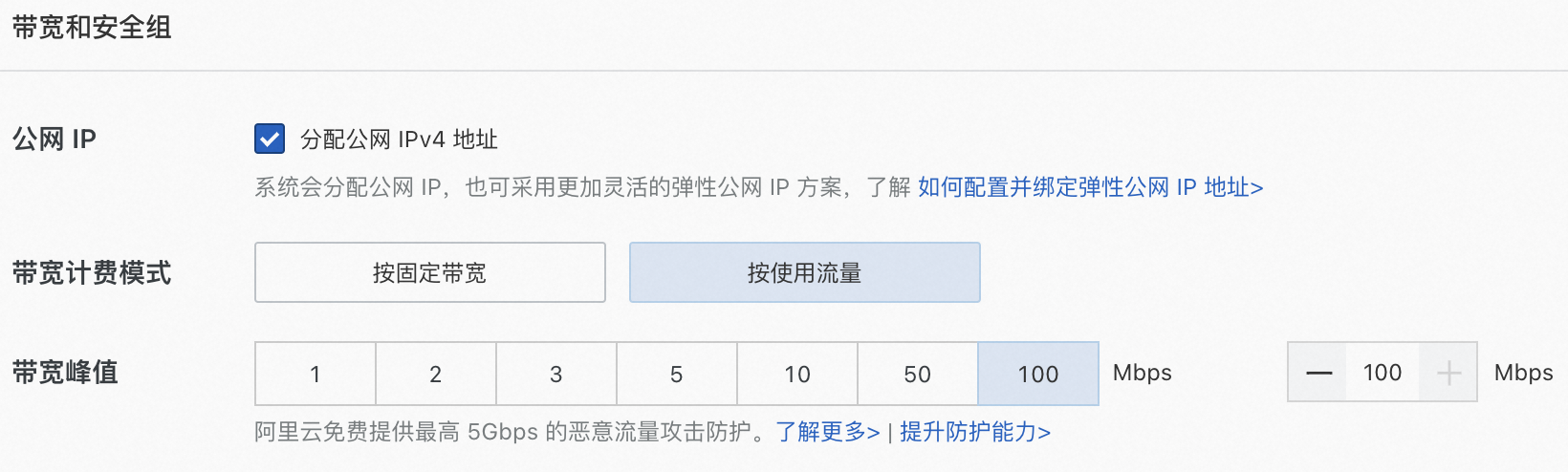
- 公网IP:选中分配公网IPv4地址,带宽计费方式选择按使用流量,带宽峰值选择100 Mbps,以加快模型下载速度。
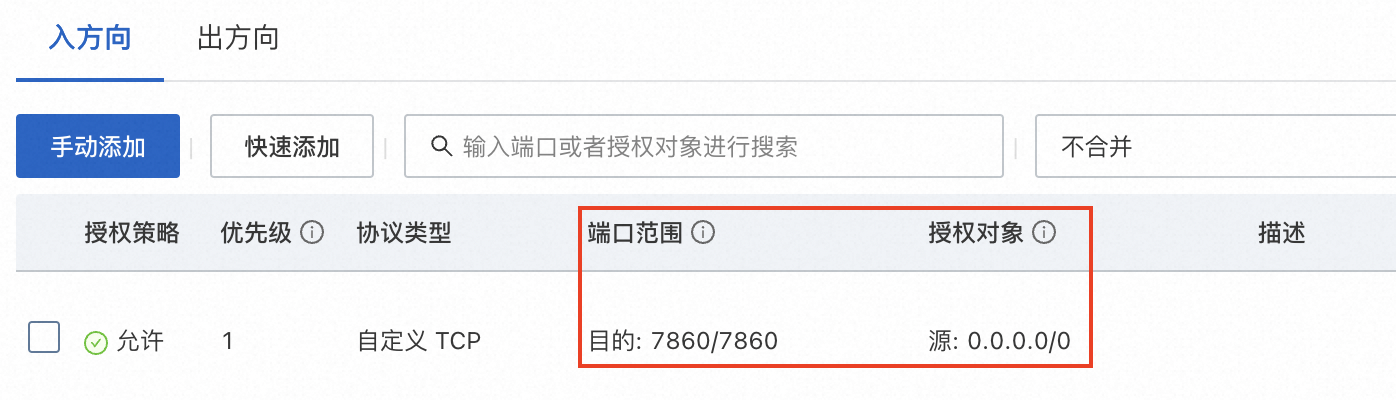
- 添加安全组规则。在ECS实例安全组的入方向添加安全组规则并放行7860端口。具体操作,请参见添加安全组规则。
- 查看驱动以及CUDA库是否安装成功。
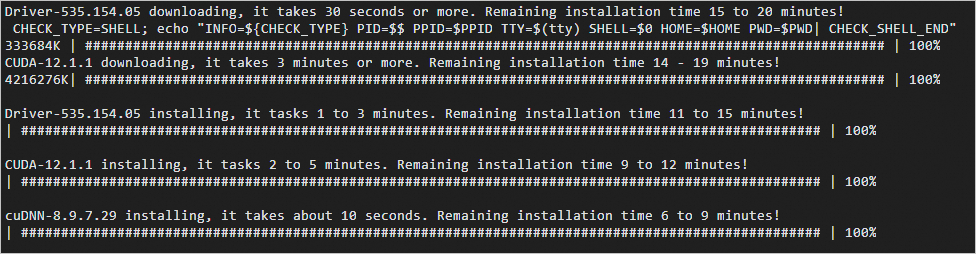
- 使用root用户远程登录ECS实例。具体操作,请参见通过密码或密钥认证登录Linux实例。首次登录ECS实例时,系统会自动安装驱动。当显示如下图所示的回显信息时,表示驱动以及CUDA库已安装成功。重要
- 系统自动安装驱动以及CUDA库时,请不要手动操作或者重启实例,否则可能会导致驱动或者CUDA库安装失败。等到安装驱动以及CUDA库完成以后,系统会自动重启。如果创建完ECS实例后,没有立即远程登录ECS实例,可能看不到类似下图的回显信息。
- 再次使用root用户远程登录ECS实例。具体操作,请参见通过密码或密钥认证登录Linux实例。
- 执行以下命令,查看GPU驱动的版本。
nvidia-smi回显信息类似下图所示。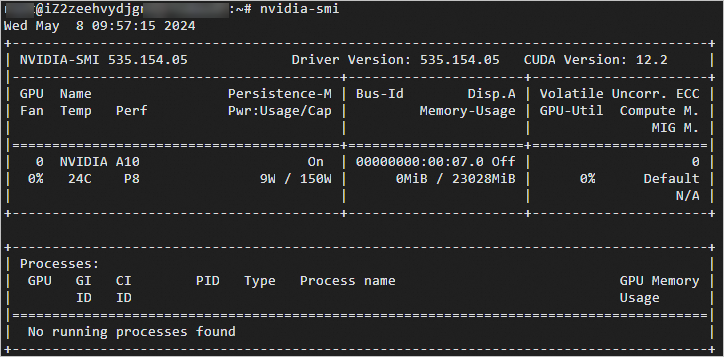
- 执行以下命令,查看CUDA库的版本。
nvcc -V回显信息如下图所示。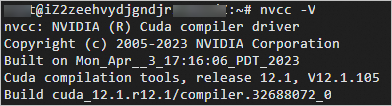
- 使用root用户远程登录ECS实例。具体操作,请参见通过密码或密钥认证登录Linux实例。首次登录ECS实例时,系统会自动安装驱动。当显示如下图所示的回显信息时,表示驱动以及CUDA库已安装成功。重要
配置软件
- 安装Python 3.11并升级pip。
- 分别执行以命令,安装Python 3.11。
apt-get update apt-get upgrade apt install -y python-is-python3 # 将默认Python改成Python3 apt install -y software-properties-common # 安装software-properties-common软件包 add-apt-repository ppa:deadsnakes/ppa # 添加PPA存储库 apt -y install python3.11 # 安装Python 3.11 update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 1 # 设置默认Python为Python 3.11 - 执行如下命令,查看Python版本。
python --version当回显如下所示时,表示已安装Python 3.11.9。
- 分别执行以命令,升级pip。
wget https://bootstrap.pypa.io/get-pip.py python3.11 get-pip.py
- 分别执行以命令,安装Python 3.11。
- 执行以下命令,安装Git和Git LFS软件。
apt install -y git git-lfs python3.11-distutils - 依次执行以下命令,安装模型所需要的Python包。
sudo apt-get install pkg-config cmake sudo apt-get install python3.11-dev pip install git+https://github.com/huggingface/transformers pip install sentencepiece==0.1.97 -i https://mirrors.aliyun.com/pypi/simple pip install peft==0.10.0 -i https://mirrors.aliyun.com/pypi/simple重要从GitHub上下载Transformers库,由于网络原因偶尔可能会不成功,建议您多尝试几次。 - 在PyTorch环境下验证GPU是否正常工作。
- 执行以下命令,进入Python运行环境。
python - 执行以下命令,验证GPU是否正常工作。
import torch torch.cuda.is_available()返回True,表示GPU正常工作。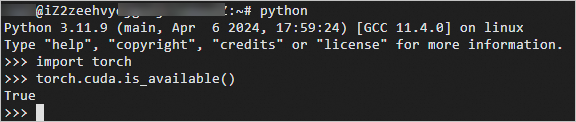
- 执行以下命令,退出Python。
quit()
- 执行以下命令,进入Python运行环境。
下载与配置模型
- 依次执行以下命令,下载tmux并创建一个tmux session。
apt install -y tmux tmux重要下载模型耗时较长,建议在tmux session中下载,以免ECS断开连接导致下载中断。 - 执行以下命令,下载Chinese-LLaMA-Alpaca模型。
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git - 执行以下命令,下载chinese-alpaca-lora-13b模型。
git clone https://www.modelscope.cn/ChineseAlpacaGroup/chinese-alpaca-lora-13b.git - 依次执行以下命令,下载llama-13b-hf。llama-13b-hf是预训练的llama 13b模型,已经转换成了Huggingface的模型格式。下载llama-13b-hf大约有40 GiB的数据,预估下载时间约30分钟,请您耐心等待。重要LLaMA是第三方提供的Huggingface格式的预训练模型数据。Meta官方发布的LLaMA模型禁止商用,并且官方暂时还没有正式开源模型权重。这里使用这个下载链接只为做演示使用,不承担任何法律责任。
pip install -U huggingface_hub pip install -U hf-transfer export HF_ENDPOINT=https://hf-mirror.com export HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download --resume-download --local-dir-use-symlinks False yahma/llama-13b-hf --local-dir llama-13b-hf - 依次执行以下命令,合并代码。
cd Chinese-LLaMA-Alpaca/ python scripts/merge_llama_with_chinese_lora.py --base_model ~/llama-13b-hf/ \ --lora_model ~/chinese-alpaca-lora-13b/ --output_type huggingface \ --output_dir ./llama_with_lora_hf命令行中需要用–output_dir命令指定一个输出目录,本示例中输出目录为/root/Chinese-LLaMA-Alpaca/llama_with_lora_hf。转换需要一段时间,需要耐心等待。 - 执行以下命令,查看转换完成后的文件。
ls -lh llama_with_lora_hf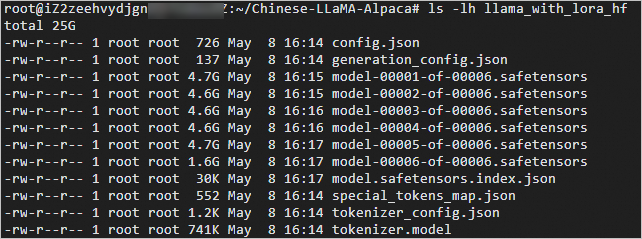
部署WebUI
- 执行以下命令,在
/root目录或者您的工作目录,下载WebUI并且进行代码部署。cd git clone https://github.com/oobabooga/text-generation-webui.git - 执行以下命令,安装代码及依赖库。重要安装代码及依赖库涉及从GitHub下载代码,可能会因为网络原因运行失败,请多试几次。
cd text-generation-webui/ pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple pip install datasets gradio rich bitsandbytes -i https://mirrors.aliyun.com/pypi/simple/ - 执行以下命令,在models目录下面生成一个软链接,指向合并后模型数据的目录。
ln -s /root/Chinese-LLaMA-Alpaca/llama_with_lora_hf/ models/llama_with_lora_hf参数说明如下:/root/Chinese-LLaMA-Alpaca/llama_with_lora_hf/:指的是合并模型存放的目录,您可以从合并代码步骤获取。models/llama_with_lora_hf:指的是模型名称,您可以修改成其他名称。
验证结果
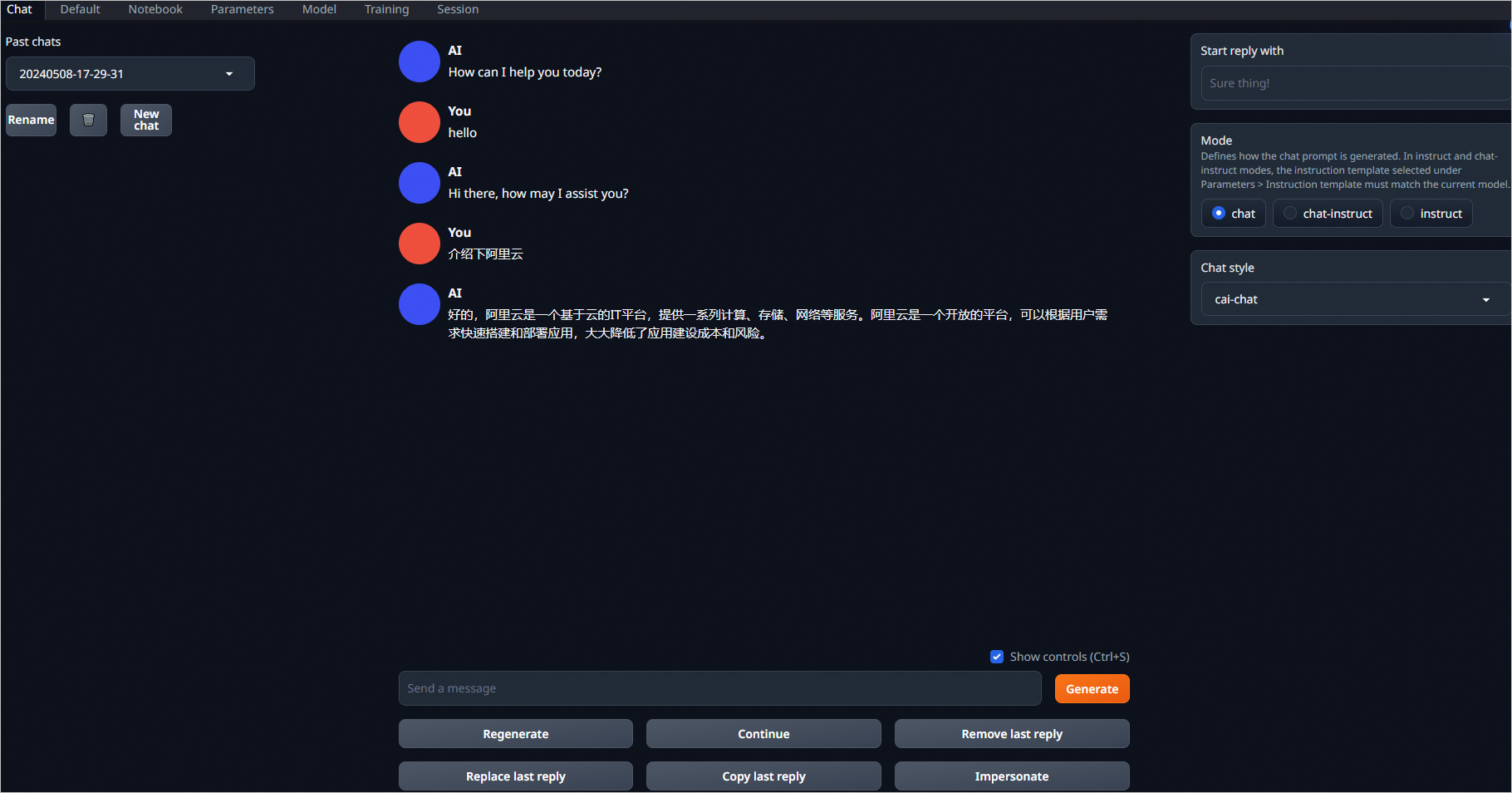
完成以上操作后,您已经成功完成了WebUI部署和个人版对话大模型的搭建。您可以在WebUI页面进行验证。
- 执行以下命令,运行WebUI。
cd text-generation-webui/ python server.py --model llama_with_lora_hf --listen --chat --load-in-8bit参数说明如下:- –model:指定的是步骤3生成的软链接的名称,不需要带前面的model/目录名。本示例软链接的名称为
llama_with_lora_hf。–listen:用于设置WebUI监听所有外部IP(不配置–listen默认只能监听本地IP),以实现从实例外访问WebUI。默认监听端口是7860,您可通过–listen-port来指定其他监听端口。–chat:用于指定默认的运行模式,本文示例为对话模式(可按需尝试其他模式)。–load-in-8bit:用于指定以8 bit模式加载模型。正常加载13B模型需要26 GB以上显存,A10显卡只有24 GB,所以需要以8bit模式加载,模型占用显存大约为15 GB。

- –model:指定的是步骤3生成的软链接的名称,不需要带前面的model/目录名。本示例软链接的名称为
- 在ECS实例页面,获取ECS实例的公网IP地址。
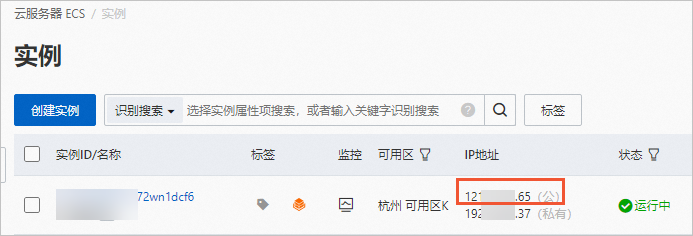
- 在浏览器中输入
http://<ECS实例公网IP地址>:7860,即可访问个人版对话大模型。您可以输入相应的问题和AI机器人进行对话。